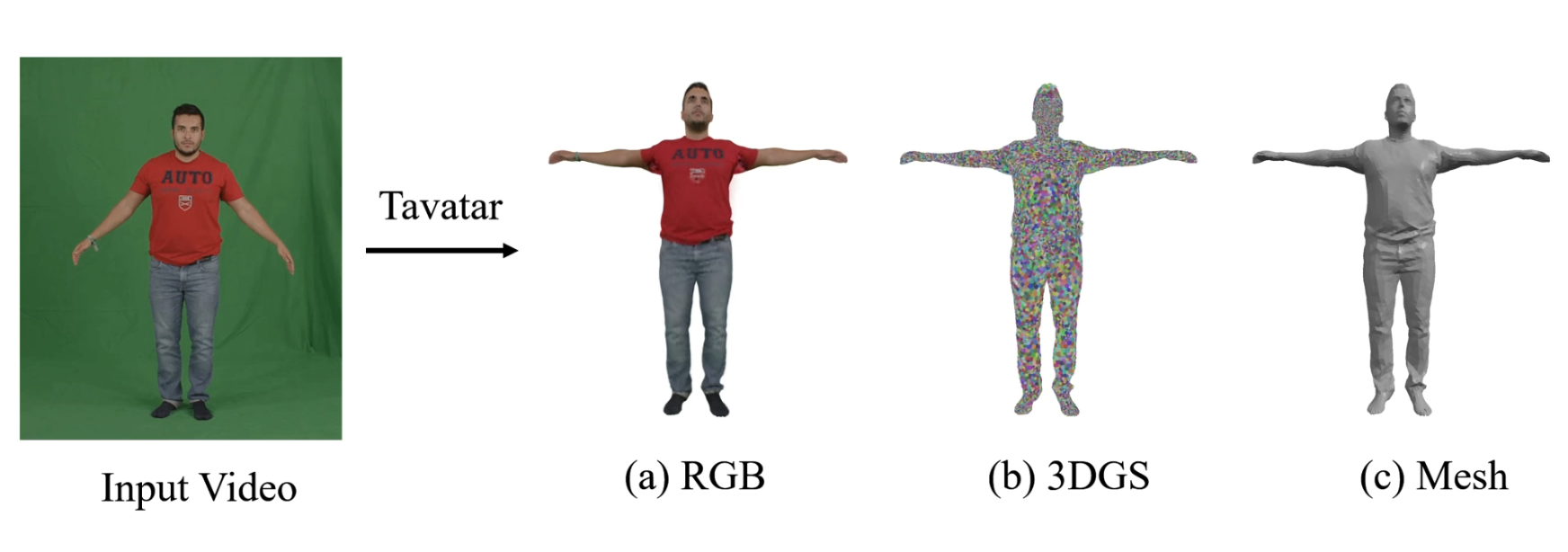
Our method constructs a topology-aware 3D Gaussian representation from monocular videos.
Compare methods side-by-side using the dual viewer interface. Select Method, Subject, and Pose from dropdowns. Enable Random Color for better 3DGS visualization.
Viewer Interactions: Use mouse to drag for rotation, scroll for zoom, and right-click + drag for panning.
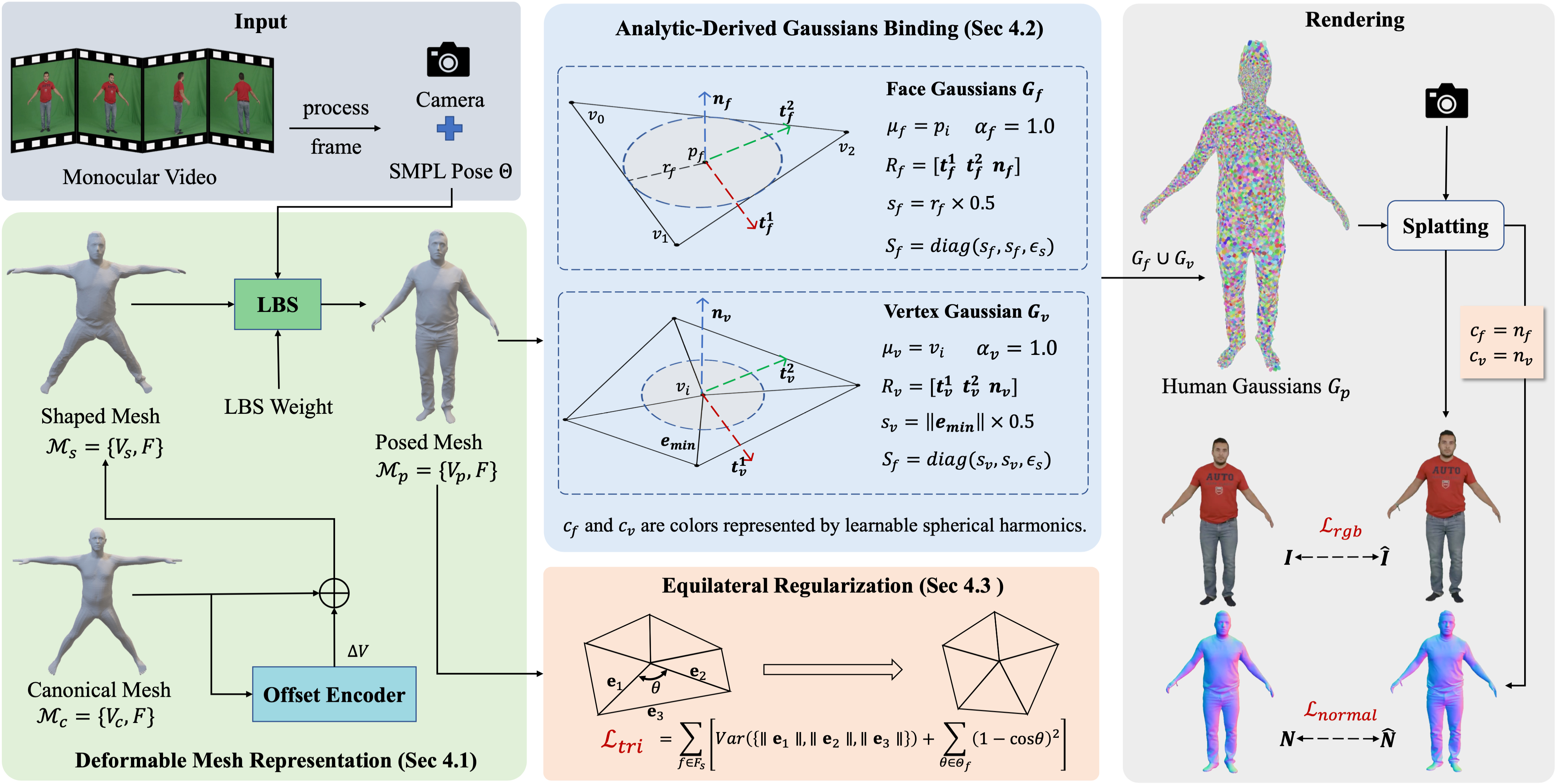
Method overview. We propose Tavatar, a geometry-driven paradigm that reconstructs high-quality animatable human avatars by analytically deriving Gaussian attributes from a deformable mesh. Our approach includes: Analytical Gaussian Attribute Derivation: All Gaussian positions, scales, and orientations are computed directly from mesh topology—rather than optimized—yielding structurally correct Gaussian placement, improved surface coverage, and pose-consistent animation across challenging motions. Equilateral Geometry Regularization: An equilateral constraint enforces stable Gaussian binding on the mesh, preventing degeneration and ensuring robust reconstruction quality, especially under large deformations and in fine-detail regions such as hands and clothing folds.
